





I. Les promesses des Web Components▲
I-A. Un standard pour les composants d'interface en JavaScript▲
La particularitûˋ de cette spûˋcification est qu'elle vient influencer la maniû´re dont nous codons nos pages HTML en y ajoutant une approche rûˋsolument modulaire. Les composants viennent se situer hiûˋrarchiquement entre le document et les ûˋlûˋmentsô ; on peut les concevoir comme des groupes autonomes d'ûˋlûˋments formant un bloc identifiable visuellement et fonctionnellement.
Ainsi, ils se substituent assez bien au concept de widgets, ces composants d'interfaces dûˋjû popularisûˋs depuis de nombreuses annûˋes par des bibliothû´ques comme jQueryUI, YUI (abandonnûˋ il y a peu par Yahoo) ou encore les widgets Dojo. Le net avantage des Web Components par rapport û ces bibliothû´ques est la simplicitûˋ d'intûˋgration, puisqu'il suffit d'utiliser la balise personnalisûˋe dans votre HTML pour charger le composant. Les dûˋveloppeurs de composants sont encouragûˋs û permettre le paramûˋtrage de ces composants directement via des attributs HTML, afin que le composant puisse ûˆtre utilisûˋ sans ûˋcrire une ligne de JavaScript. Toutefois, une simple dûˋclaration HTML ne peut ûˋgaler la flexibilitûˋ du paramûˋtrage et de l'initialisation JavaScript, c'est pourquoi certains Web Components complexes s'utilisent encore par le biais d'une API JavaScript.
Ce nouveau standard devrait donc en thûˋorie sonner le glas de ces diffûˋrentes bibliothû´ques UI, ce qui fait que nous n'aurions plus û nous prûˋoccuper des dûˋpendances propres û chaque widget trouvûˋ sur le Net. En thûˋorie seulement, car on trouve dûˋjû de nouvelles bibliothû´ques regroupant des Web Components avec un format, un style et des spûˋcificitûˋs qui leur sont propresô : ô Polymer de Google et Brick de Mozilla par exemple. Pour l'instant, ils font des efforts en matiû´re d'interopûˋrabilitûˋ, mais nous n'avons aucune garantie que cela restera le cas avec l'apparition d'autres bibliothû´ques de ce genre. Malheureusement, les bibliothû´ques de Web Components semblent tomber dans les mûˆmes travers que les bibliothû´ques de widgets en leur temps.
I-B. Simplifier et ûˋtendre la syntaxe HTML▲
Une critique rûˋcurrente du HTML par les dûˋveloppeurs d'applications web riches est le nombre restreint d'ûˋlûˋments û dispositionô : des grands absents comme les barres d'onglets, les tooltips (infobulles) ou les overlays (masques d'arriû´re-plan) se font toujours dûˋsirer. Tout le problû´me du point de vue des organismes de standardisation est de dûˋfinir la nature de ces ûˋlûˋments, et de s'assurer qu'ils prûˋsentent un sens pour tous les usages et contextes qu'offre le Web. Par exemple, quelle diffûˋrence y a-t-il entre une barre d'onglets, un menu accordûˋon, et une barre de navigationô classique chargeant du contenu via AJAX ? Certes, chacun dispose de caractûˋristiques visuelles particuliû´res qui nous permettent de les diffûˋrencier. Mais sur le plan sûˋmantique et fonctionnel, c'est une autre affaire. C'est pourquoi les descriptions des ûˋlûˋments standards sont volontairement abstraitesô : <article> ne contient pas forcûˋment un article au sens publication, tandis que <figure> peut convenir û la fois pour des images, des schûˋmas ou des bouts de code.
Puisqu'avec les Web Components, chacun est libre de crûˋer les balises de son choix, le futur HTML sera sans doute beaucoup plus diversifiûˋ et concret. Bonne ou mauvaise nouvelleô ? Les dûˋveloppeurs s'en rûˋjouissent au premier abord, mais un HTML trop spûˋcifique et disparate pourrait nuire û l'ubiquitûˋ du Webô : si les experts du W3C et du WHATWG prennent bien le temps de peser le pour et le contre û l'introduction d'un nouvel ûˋlûˋment, il y a peu de chances que nous fassions preuve d'autant de rûˋflexion (surtout un vendredi soir sur un projet en retard ![]() ). Un ûˋlûˋment barre d'onglets <tabs-bar> peut ûˆtre une fausse bonne idûˋe s'il doit ûˆtre remaniûˋ en menu dûˋroulant sur les petits ûˋcrans.
). Un ûˋlûˋment barre d'onglets <tabs-bar> peut ûˆtre une fausse bonne idûˋe s'il doit ûˆtre remaniûˋ en menu dûˋroulant sur les petits ûˋcrans.
Le Web se transforme sans cesse et ses usages s'ûˋtendent û de nouvelles classes d'appareils. Ce phûˋnomû´ne semble s'accentuer avec le temps, ce qui me laisse û croire que la vision que nous avons du Web est encore trû´s limitûˋeô : le Web n'a que 25 ans, et il a dûˋjû changûˋ de visage plus d'une fois (Web 2.0, rûˋvolution mobileãÎ). Aujourd'hui plus que jamais, nous avons besoin de prendre du recul sur la conception de nos pages Web et de nous concentrer sur le contenu, û travers un HTML gûˋnûˋrique et sûˋmantique. Un HTML û l'abstraction et aux limites nûˋcessaires, qui ne parte pas dans toutes les directions et qui ne se banalise pas, car son rûÇle est bien plus important qu'on ne le croit.

I-C. Standardiser le templating cûÇtûˋ client▲
L'introduction des Web Components amû´ne ûˋgalement la balise <template>, dont la fonction est trû´s particuliû´reô : elle contient un fragment de HTML qui sera chargûˋ sans ûˆtre activûˋô : c'est-û -dire que tous les ûˋlûˋments û l'intûˋrieur sont inertes avant d'ûˆtre utilisûˋsô : les images ne sont pas chargûˋes, les <script> ne sont pas exûˋcutûˋs, les <video> et <audio> ne sont ni chargûˋs ni jouûˋsãÎ Ce HTML inerte peut par la suite ûˆtre ô¨ô activûˋô ô£ en copiant son contenu et en l'insûˋrant en JavaScript û l'endroit dûˋsirûˋ dans le document.
Cette nouvelle balise est pressentie pour standardiser le templating cûÇtûˋ client, comme le souligne cet article sur HTML5Rocks.com . Or, il n'en est rien. Comme nous le verrons en section IV de cet article, cet objectif est bien trop large et abstrait pour ûˆtre atteignable. Les auteurs de la spûˋcification en ont bien conscience et n'ont pas mûˆme pas essayûˋ d'aller dans cette voie. En rûˋalitûˋ, la spûˋcification est trû´s limitûˋe dans son champ d'application. Il s'agit simplement d'un conteneur de HTML û rûˋserver pour plus tard, ce que beaucoup de bibliothû´ques de templating client avaient dûˋjû rûˋussi û faire par le biais de balises <script> avec un attribut type spûˋcial.
Tous les autres usages envisagûˋs, et en particulier son rûÇle de pierre angulaire dans les solutions de templating cûÇtûˋ client, ne sont que pure extrapolation de la part des dûˋveloppeurs. Actuellement, la spûˋcification prûˋsente plus de contraintes que d'avantages comparûˋe aux solutions existantes û base de <script>. Elle a le mûˋrite d'enfin apporter un standard pour un mûˋcanisme utilisûˋ et ûˋprouvûˋ depuis des annûˋes. Mais tout comme les imports HTML, elle semble arriver trop tard et les ûˋlûˋments <template>seuls ne servent û rien sans JavaScript pour les activer.
II. Custom Elementsô : <mon-element-a-moi>▲
II-A. Adieu les dûˋfinitions de type de document (DTD)▲
HTML, un descendant de SGML (Standard Generalized Markup Language), a pu jusqu'û sa version 4 ûˆtre dûˋcrit par des DTDDûˋfinition de type de document, c'est-û -dire des descriptions techniques formelles du langage qui faisaient notamment la liste des balises admises dans le langage.
<!ELEMENT IMG - O EMPTY -- Embedded image -->
<!ATTLIST IMG
%attrs; -- %coreattrs, %i18n, %events --
src %URI; #REQUIRED -- URI of image to embed --
alt %Text; #REQUIRED -- short description --
longdesc %URI; #IMPLIED -- link to long description
(complements alt) --
name CDATA #IMPLIED -- name of image for scripting --
height %Length; #IMPLIED -- override height --
width %Length; #IMPLIED -- override width --
usemap %URI; #IMPLIED -- use client-side image map --
ismap (ismap) #IMPLIED -- use server-side image map --
>GrûÂce aux DTDDûˋfinition de type de document, les ûˋlûˋments de la page sont systûˋmatiquement dûˋcrits et normalisûˋs. Ces ûˋlûˋments connus, les navigateurs disposent d'informations pour dûˋduire la hiûˋrarchie du document et le reprûˋsenter plus efficacement.
Parmi les cousins les plus connus du HTML, XML offre bien plus naturellement aux dûˋveloppeurs la possibilitûˋ d'utiliser leurs propres balises pour dûˋcrire les donnûˋesô ; les DTD qui les accompagnent font office de contrat d'interface trû´s fiable, faisant du XML un bon choix pour la communication entre serveurs et web services.
HTML a pris un autre chemin. Les interprûˋteurs dans les navigateurs sont conûÏus pour ûˆtre trû´s tolûˋrants, en acceptant les erreurs de syntaxe et en tentant de les corrigerô : c'est pourquoi la plupart des navigateurs web parviennent û fermer automatiquement certaines balises, û afficher des balises inconnues ou û ignorer les attributs et valeurs non standardisûˋes. De ce fait, les dûˋveloppeurs Web ont toujours fait preuve de beaucoup de nûˋgligence sur la qualitûˋ et la validitûˋ stricte du HTML qu'ils produisaient. Si vous avez dûˋjû utilisûˋ un validateur HTML (on en trouve des dizaines gratuits en ligne, dont celui du W3Cô : http://validator.w3.org/), vous avez sans doute dûˋjû essayûˋ de faire valider certains sites grand public et le nombre d'erreurs relevûˋes a dû£ vous surprendre.

Ainsi, les dûˋveloppeurs HTML n'ont jamais vraiment portûˋ grande importance aux DTD. Depuis HTML5, les ûˋlûˋments n'ont d'ailleurs plus û respecter les contraintes d'une DTDô ; ce que les dûˋveloppeurs ont trû´s bien accueilli par le simple fait que cela leur simplifiait la dûˋclaration du DOCTYPEô :
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"
"http://www.w3.org/TR/html4/loose.dtd"><!DOCTYPE html>Avec les Custom Elements (ûˋlûˋments personnalisûˋs), cette flexibilitûˋ va encore plus loin puisque de nouveaux types d'ûˋlûˋments peuvent ûˆtre dûˋfinis cûÇtûˋ clientô a posteriori de la crûˋation du documentô ; ce que n'a jamais permis une DTDDûˋfinition de type de document. La majoritûˋ des articles autour des Custom Elements ne font d'ailleurs aucune mention des DTDDûˋfinition de type de document, ce que je trouve trû´s ûˋtonnant. Du temps du HTML4, si on avait demandûˋ û un dûˋveloppeur de dûˋclarer des balises personnalisûˋes, il aurait tout de suite pensûˋ û une DTD personnalisûˋe.
Malgrûˋ le fait que le HTML5 se soit ûˋmancipûˋ des DTDDûˋfinition de type de document, on pourrait tout de mûˆme en parler ne serait-ce qu'û titre de comparaison.
II-B. Shadow DOMô : le cache-misû´re officiel▲
Les Custom Elements sont composûˋs d'ûˋlûˋments HTML standards. Ce ne sont pas des nouvelles briques mais un assemblage de briques existantes agrûˋmentûˋes de JavaScript et de dûˋclarations CSS isolûˋes. Il est important de comprendre que tout ce que l'on peut faire avec les Custom Elements peut dûˋjû ûˆtre fait aujourd'huiô : il s'agit simplement d'un emballage, d'un paquet cadeau û destination des dûˋveloppeurs, destinûˋ û normaliser la dûˋfinition et l'intûˋgration d'ûˋlûˋments d'interface aussi appelûˋs widgets, bien que le terme semble ûˆtre passûˋ de mode.
Puisque tout l'intûˋrûˆt des Custom Elements est d'avoir un bel emballage, il faut veiller û ce que le contenu de ces ûˋlûˋments soit bien emballûˋ et cachûˋ d'un regard extûˋrieurô tant que l'on n'a pas ouvert la boûÛte: c'est de lû que vient l'idûˋe du Shadow DOM.
Mais que cherche-t-on û cacher exactementô ? Qu'y a-t-il de si affreux et verbeux dans notre HTML pour que l'on souhaite le faire disparaûÛtreô ? Tous les exemples donnûˋs dans les articles sur ce sujet sont criants de vûˋritûˋô : c'est l'utilisation abusive de markup û des fins de mise en forme.
En effet, il semble tout û fait normal pour certains auteurs d'articles sur le sujet que l'on distingue en HTML un markup de prûˋsentation d'un markup de contenu. Le markup pour le style, ce n'est pas sans rappeler la mise en page par tableaux qui avait ses ûˋmules entre 1995 et 2005ô : utiliser des ûˋlûˋments <table>, <tr> et <td> pour aligner et dimensionner les ûˋlûˋments au mûˋpris de la sûˋmantique du document. Si la mise en page par tableaux est aujourd'hui considûˋrûˋe comme une mauvaise pratique (et mûˆme source de moqueries pour certains web designer seniors), force est de constater que l'utilisation abusive de <div> et de <span>, aussi appelûˋe ô¨ô soupe de divô ô£, ne fait guû´re mieux. On comprend mieux pourquoi on souhaite la cacher.
Voici un extrait des Web Components Best Practicesô issu du site communautaire webcomponents.org:
Don't put too much in Shadow DOM : Shadow DOM allows you to stuff a bunch of complex junk out of sight. However, that's not an excuse to have as many DOM elements as you want in your shadow, as more elements will still lead to worse performance. In addition, try to keep your configuration and state visible by keeping anything semantic exposed in the logical DOM. Cruft goes in the Shadow; semantic stuff doesn't.
Traduction: Ne chargez pas trop votre Shadow DOM : Le Shadow DOM vous autorise û fourrer votre camelote û l'abri des regards indiscrets. Cependant, ce n'est pas une excuse pour avoir autant d'ûˋlûˋments DOM que vous avez envie dans votre Shadow DOM, car un nombre croissant d'ûˋlûˋments conduira immanquablement û empirer les performances. De plus, essayez de garder votre configuration et vos ûˋtats applicatifs visibles en maintenant tout ce qui relû´ve de la sûˋmantique dans le DOM logique. Vos cochonneries vont dans le Shadow DOM, les ûˋlûˋments sûˋmantiques non.
S'agit-il lû de l'aveu qu'un HTML purement sûˋmantique est impossibleô ? Ou juste trop difficile û atteindreô ? Notez les mots employûˋsô : junk (camelote) et Cruft (cochonneries). Doit-on vraiment accepter cela et normaliser un HTML cameloteô ?
Mon opinion est qu'il ne devrait pas y avoir du tout de markup de prûˋsentation. D'ailleurs, toutes les balises dites de prûˋsentation telles que <center>, <font> ou <b> ont ûˋtûˋ dûˋprûˋciûˋes ou adaptûˋes en HTML5. S'il reste certains cas nûˋcessitant de modifier le markup uniquement û des fins de style, alors les standards doivent ûˋvoluer pour rûˋgler ces cas au lieu de les tolûˋrer et de chercher û les dissimuler.
Le Shadow DOM est un cache-misû´re. Certains diront qu'il s'agit d'une solution pragmatique et court-termiste û ce problû´me. Je pense personnellement que c'est tout sauf une solutionô : il ne rûˋsout pas le problû´me du HTML trop verbeux, mais se contente de cacher la poussiû´re sous le tapis. Au contraire, en masquant le problû´me, cela pourrait encourager les dûˋveloppeurs û persister dans cette mauvaise pratique et ne faire qu'empirer les choses. D'autres diront qu'il prûˋsente un intûˋrûˆt pour l'isolation des rû´gles CSS. Je leur rûˋpondrai qu'il existe d'autres moyens pour y parvenir sans avoir û fragmenter le document: <style scoped> @import "composant.css"; </style>
HTML5 a amenûˋ une vingtaine de nouvelles balises liûˋes û la structure et û la sûˋmantique du document, tandis que les ûˋvolutions de CSS rûˋduisent peu û peu la nûˋcessitûˋ de recourir û de multiples ûˋlûˋments û des fins de mise en forme. Il s'agit clairement de la direction û suivre, en s'attaquant au problû´me de front. C'est pourquoi le Shadow DOM doit rester û sa place: û l'ombreô !
II-C. Pas si custom que ûÏa▲
Avec les Custom Elements, on s'autorise û ce que le HTML parte dans toutes les directions û partir du moment oû¿ les propriûˋtûˋs de ces nouveaux ûˋlûˋments accompagnent le documentô : est-ce rûˋellement une bonne idûˋeô ? Outre le fait de charger un peu plus encore les requûˆtes, on vient surcharger les propriûˋtûˋs ûˋtablies par dûˋfaut par le navigateur pour chaque ûˋlûˋment.
En effet, chaque navigateur implûˋmente sa propre feuille de style, appelûˋe User Agent Stylesheet, qui dûˋfinit les propriûˋtûˋs CSS de base des ûˋlûˋments des pages que vous consultez. Ce sont ces rû´gles que vous surchargez en dûˋfinissant vos propres feuilles de style pour vos sites. Or, les User Agent Stylesheets varient selon le navigateurô ; c'est ce qui explique que vous n'ayez pas tout û fait le mûˆme rendu d'un navigateur û un autre (ûÏa et quelques dûˋtails d'implûˋmentation des moteurs de rendu).
Sur un mûˆme navigateur, elles peuvent varier ûˋgalementô ; par l'ajout d'extensions, de feuilles de styles propres û l'utilisateur (userstylesheets), de dûˋtails spûˋcifiques au terminal (par exemple un navigateur Android selon s'il est installûˋ sur un smartphone ou une tablette), ou encore d'outils dûˋdiûˋs û certains handicapsô : ces outils peuvent agrandir les textes, augmenter le contraste, fournir des moyens de saisie et de navigation assistûˋs, simplifier la mise en page, etc.
Ces variations sont utiles et nûˋcessairesô : le dûˋveloppeur ne devrait en aucune faûÏon chercher û les annihiler pour que son site s'affiche de la mûˆme maniû´re sur tous les navigateurs. Or, plus on dûˋfinit les propriûˋtûˋs d'ûˋlûˋments, moins les rû´gles par dûˋfaut s'appliquent. Ce contrûÇle absolu de l'apparence et du comportement du composant peut ûˋgalement poser des problû´mes d'accessibilitûˋ. Heureusement, l'accessibilitûˋ n'a pas ûˋtûˋ oubliûˋe par tous les dûˋveloppeurs de Web Components et fait dûˋjû partie des prûˋoccupations des auteurs de Polymer; il faudrait idûˋalement qu'elle ne soit oubliûˋe par personne.
Pour mieux comprendre quel est le problû´me exactement, prenons un exemple parlant et intûˋressons-nous un moment au cas du sûˋlecteur de dates (datepicker). C'est un cas que j'ai rencontrûˋ plusieurs fois et qui m'a vraiment aidûˋ û comprendre les enjeux de la standardisation d'ûˋlûˋments.
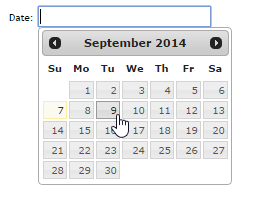
En HTML4, les boûÛtes de saisie sont trû´s limitûˋes dans les formulaires et le seul moyen de sûˋlectionner une date est de la saisir dans un certain formatô : DD/MM/YYYY par exemple. Une validation de format est ensuite effectuûˋe cûÇtûˋ serveur, et parfois cûÇtûˋ client ûˋgalement. Tout cela est assez fastidieux û la fois pour l'utilisateur comme pour le dûˋveloppeur. Ainsi, le widget DatePicker est rapidement devenu un classique des bibliothû´ques de widget. Voilû û quoi ressemble celui de jQueryUIô :
Ensuite, avec HTML5 est apparu <input type="date">. Maintenant que le type de donnûˋe attendu est connu des navigateurs, ceux-ci peuvent proposer leurs propres datepicker conûÏus spûˋcifiquement pour chaque terminal et navigateurô ; ce qui se traduit par un moyen de saisie plus adaptûˋ et ergonomique. Opera a ûˋtûˋ parmi les premiers û implûˋmenter un datepickerô ; ils sont ensuite apparus sur divers navigateurs mobiles. Voilû un aperûÏu de certains datepicker ô¨ô natifsô ô£ existantsô :

Notez la diffûˋrence d'ergonomie entre un datepicker pour souris comme celui de Chrome et un datepicker pour ûˋcran tactile comme sur iOSô ; ou la diffûˋrence entre les datepicker Android selon la taille d'ûˋcran. Les datepicker JavaScript ne pourront jamais s'adapter aussi bien selon le contexteô ; de plus, les utilisateurs sont accoutumûˋs û utiliser les composants natifs fournis par leur navigateur et leur systû´meô : ils sauront l'utiliser sans problû´me.
Certes, tous les navigateurs ne proposent pas encore de widgetsô : Firefox et Internet Explorer considû´rent encore ces types de champ comme de simples champs texte. Mais il est possible de dûˋtecter le support de datepicker natif et de charger un datepicker JavaScript comme solution de secours (un tutoriel est disponible ici). Le widget pourrait faire lui-mûˆme ce test, ou au moins proposer un paramûˋtrage û cet effet. Cependant, ce n'est gûˋnûˋralement pas l'approche choisie par les dûˋveloppeurs de ces widgetsô : ils prûˋfû´rent choisir trû´s prûˋcisûˋment le style et le comportement de leur widget, quitte û nûˋgliger l'adaptation au terminal.
Et c'est le mûˆme topo pour les Web Componentsô : alors que la spûˋcification est toujours û l'ûˋtude, on voit dûˋjû plusieurs composants sûˋlecteurs de date faire leur apparition, dont la grande majoritûˋ ne se prûˋoccupent pas de tester le support de <input type="date">. Il y a de rares exceptions comme celui-ci qui agit comme un polyfill. Mais pourquoi alors utiliser un Custom Element quand un polyfill sur l'ûˋlûˋment input fonctionne tout aussi bienô ?
En rûˋsumûˋ, un des risques majeurs liûˋs û l'usage excessif de Custom Elements est celui de surcharger excessivement les styles par dûˋfaut d'ûˋlûˋments standards ou de ne pas utiliser les ûˋlûˋments standards appropriûˋs, ce qui nuit û l'ergonomie et l'accessibilitûˋ de vos composants.
III. HTML importsô : arrivûˋs aprû´s la bataille▲
III-A. Alors qu'on ne les attendait plus▲
Nous composons nos pages HTML de maniû´re modulaire depuis de nombreuses annûˋes. L'inclusion de HTML est une des fonctionnalitûˋs les plus basiques de tout langage de vues cûÇtûˋ serveur ; elle prûˋfigure souvent dans les tutoriels. Ainsi, ces lignes de code ne devraient pas vous ûˆtre inconnuesô :
<?php include 'header.php'; ?>
<jsp:include page="header.jsp" />
<!-- #include file="header.asp" -->Sans langage serveur, c'est-û -dire avec un serveur web statique, il existe ûˋgalement plusieurs moyens d'inclure une page dans une autre. Lorsque j'ai fait mes dûˋbuts en dûˋveloppement web il y a douze ans, les framesets ûˋtaient û la modeô :
<frameset rows="20%,80%">
<frame name="header" src="header.html" />
<frame name="main" src="main.html" />
<noframes>Your browser does not support frames.</noframes>
</frameset>Ensuite on a voulu apporter une solution moins intrusive et plus discrû´teô : les iframes
<iframeô src="header.html"></iframe>Puis on s'est aperûÏus qu'en bricolant un peu, on pouvait se dûˋbrouiller avec JavaScript pour composer nos vues tout en conservant un seul documentô :
<script src="header.html.js"></script>document.write("<h1>contenu ûˋchappûˋ de header.html ici</h1>");Enfin, AJAX est arrivûˋ et tout est devenu beaucoup plus facileô :
<script>
function include(src){
var scriptRef = document.scripts[document.scripts.length-1];
var xhr = new XMLHttpRequest();
xhr.onreadystatechange = function(){
if (xhr.readyState==4 && xhr.status==200){
scriptRef.outerHTML = xhr.responseText;
}
};
xhr.open("GET", src, true);
xhr.send();
}
</script>
</head>
<body>
<script>include("header.html");</script>Nous avons donc aujourd'hui tout un panel de solutions ûˋprouvûˋes û disposition. La derniû´re en date, AJAX, est utilisûˋe couramment depuis 2006, soit depuis plus de huit ans. Et voilû qu'en 2014 arrive timidement une spûˋcification pour les imports HTML. Encore au statut de Working Draft au W3C, on peut espûˋrer dans le meilleur des cas l'utiliser û la mi-2015 avec un polyfill AJAX comme parachute. Mais qu'avons-nous û y gagner û utiliser cette nouvelle spûˋcificationô par rapport û AJAX ou de la composition cûÇtûˋ serveur ? Les solutions actuelles basûˋes sur AJAX sont plus flexibles et leur large support jouera en leur faveur encore plusieurs annûˋes.
III-B. Un import seul ne sert û rien▲
Les imports HTML ne font pas vraiment ce qu'ils sont supposûˋs faire au premier abordô : ils n'ajoutent aucun HTML directement dans votre document. Ils se contentent de charger le document HTML afin que vous puissiez l'exploiter ensuite en JavaScript. Est-ce que vous vous attendiez û celaô ? Alors que toutes les instructions d'import dans les langages serveur comme PHP, JSP ou ASP chargent le contenu et l'insû´re û l'endroit de l'instruction, un import HTML ne fait rien du tout avec le contenu. C'est totalement contre-intuitif et ne suit pas les autres comportements de la balise <link>. Imaginez que les feuilles de styles CSS importûˋes ne s'appliquent pas par dûˋfaut sur le document, et qu'il faille les activer manuellement en JavaScript.
Par ailleurs, cela rend caduc l'avantage supposûˋ de cette solution comparûˋe û celles qu'on utilisait jusque-lû ô : l'import de HTML par balises <script> ou par AJAX nûˋcessite ûˋgalement un recours au JavaScript, avec un code de taille similaireô :
function include_AJAX(src){
var scriptRef = document.scripts[document.scripts.length-1];
var xhr = new XMLHttpRequest();
xhr.onreadystatechange = function(){
if (xhr.readyState==4 && xhr.status==200){
scriptRef.outerHTML = xhr.responseText;
}
};
xhr.open("GET", src, true);
xhr.send();
}
function include_import(src){
var scriptRef = document.scripts[document.scripts.length-1];
var link = document.createElement('link');
link.rel = 'import';
link.onload = function(e) {
var body = link.import.querySelector("body").cloneNode(true);
scriptRef.outerHTML = body.innerHTML;
};
link.href = src;
document.head.appendChild(link);
}Ce qui amû´ne des incohûˋrences assez amusantes, par exemple dans l'article de HTML5Rocks:
AJAXô -ô I loveô xhr.responseType="document", but you're saying I need JS to load HTML? That doesn't seem right.
J'adore xhr.responseType="document", mais vous dites que j'ai besoin de JavaScript pour charger du HTMLô ? ûa ne semble pas ûˆtre l'idûˋal.
Et plus loinãÎ
Including an import on a page doesn't mean "plop the content of that file here". It means "parser, go off an fetch this document so I can use it". To actually use the content, you have to take action and write script.
Inclure un import dans une page ne signifie pas ô¨ô mets le contenu de ce fichier iciô ô£. Cela signifieô : ô¨ô parseur, va charger ce document afin que je puisse l'utiliserô ô£. Pour utiliser concrû´tement le contenu, vous devez agir dessus en JavaScript.
Il est ûˋvident que l'on importe du HTML pour se servir de ce contenuô : alors, d'oû¿ vient cette drûÇle d'idûˋe de ne pas pouvoir se servir du contenu sans recourir au JavaScriptô ? Justement du fait qu'ils arrivent trop tardô : les solutions complexes mises en place dans les frameworks JavaScript pour gûˋrer les vues et sous-vues proposent un panel de fonctionnalitûˋs que HTML seul ne pourra jamais rivaliser avec. L'utilisation de JavaScript est une trappe de sortie pour la spûˋcification qui lui permet d'esquiver sa pauvretûˋ apparente et ne pas devoir faire face û un constat amerô : celui qu'elle arrive avec quinze ans de retard.
IV. La balise <template>ô : la coquille vide qui veut rûˋgner sur l'ocûˋan▲
IV-A. Mille solutions û un seul problû´me▲
Il y a un an, je publiais ici un article dûˋcrivant tout ce qu'il y a û savoir sur le templating cûÇtûˋ client. J'ai ûˋcrit cet article en m'imposant une consigneô : celle de ne pas privilûˋgier une approche plutûÇt qu'une autre, mais au contraire de toutes les parcourir, les illustrer par l'exemple et les comparer.
En explorant les diffûˋrentes approches, je me les suis reprûˋsentûˋ en les positionnant sur un axe simpleô : cet axe va de ô¨ô Full Logicô ô£ û ô¨ô Logic-lessô ô£ selon la quantitûˋ de logique prûˋsente dans le template. Mais les diffûˋrences vont bien au-delû de ûÏa. Tout comme on ne peut pas rûˋduire la politique û la gauche ou la droite, on ne peut pas rûˋsumer une solution de templating û la richesse syntaxique de ses templates. Le temps de rendu, la prûˋ-compilation, le pre-processing, les mûˋthodes de rendu partiel, l'asynchronicitûˋ du rendu ou encore l'empreinte sur le DOM sont autant de critû´res û prendre en compte.
La conclusion de cet article sur le templating cûÇtûˋ client ûˋtait sans appelô : il existe des tas de solutions diffûˋrentes avec des approches diffûˋrentes. Dû´s lors, comment une seule spûˋcification, ou devrais-je dire un seul ûˋlûˋment, parviendrait-il û remplacer ce panorama de solutionsô ?
IV-B. Parce qu'il faut les mettre dans une case▲
La rûˋponse û la question prûˋcûˋdente est trû´s simpleô : il n'y parviendra pas. Et il n'a jamais ûˋtûˋ question dans la spûˋcification de ne serait-ce qu'essayer d'arriver û la cheville d'une solution de templating existante aujourd'hui. Je pense que l'introduction de la balise <template> rûˋpond bûˆtement au besoin de mettre le templating client dans une caseô ; comme s'il fallait sous-entendre son existence d'une quelconque maniû´re dans une section de la spûˋcification HTML.
Une case ou plutûÇt une boûÛte noire. En effet, pour essayer de convenir au plus grand nombre de mûˋthodes de templating, les auteurs de la spûˋcification ont voulu que le contenu HTML dans cet ûˋlûˋment soit totalement inerte. Ainsi, il n'interfû´re pas avec le reste du document tant qu'il n'a pas ûˋtûˋ activûˋ en JavaScriptô ; on laissera le soin û chaque bibliothû´que de templating de l'activer au moment dûˋsirûˋ et de la maniû´re qui lui sied.
En nommant cet ûˋlûˋment <template>, on peut lûˋgitimement dire qu'il y a tromperie sur la marchandise. Ne cherchez pas comment vous pouvez vous servir de cet ûˋlûˋment pour concrû´tement ûˋcrire des templates. Cet ûˋlûˋment ne fait rien de base, mûˆme pas d'interpolation de donnûˋesô ! Aucune instruction logique, aucune rûˋfûˋrence û un modû´le de donnûˋes. Rien de tout ûÏa. C'est une boûÛte vide.
En rûˋalitûˋ, cet ûˋlûˋment est lû uniquement pour remplacer le point d'ancrage des templates des solutions existantes qui est gûˋnûˋralement une balise <script> avec un type inconnu du navigateur pour l'empûˆcher de tenter de l'interprûˋterô :
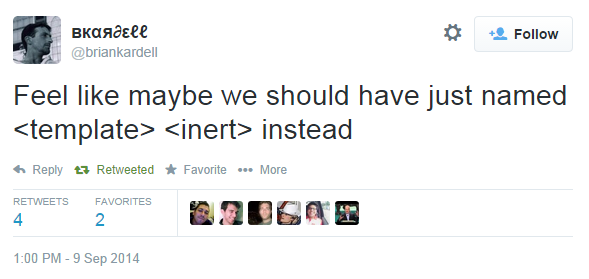
<script id="mon-template" type="text/x-handlebars-template">Il ne remplace donc absolument pas toutes les bibliothû´ques de templating existantes, contrairement û ce que le nom de l'ûˋlûˋment pourrait laisser supposer. Cela a laissûˋ perplexe beaucoup de gens, et certains participants û l'ûˋlaboration de cette spûˋcification regrettent ce nommageô :
IV-C. Une utopie de standard▲
Pour essayer de convenir û toutes les approches, la spûˋcification a optûˋ pour en faire le moins possibleô ; û vrai dire presque rien. Mais le peu qu'elle fait sort dûˋjû du cadre de certaines solutions de templating, notamment celles qui viennent s'interfacer sur des ûˋlûˋments du DOM dûˋjû actifs dans le document avant le rendu du template. On peut aussi se demander comment cette spûˋcification va permettre de gûˋrer les ûˋtats, les saisies formulaire, la compression ou prûˋcompilation des templates, les instructions logiques avancûˋes qui influent sur la structure du DOM... Autant de questions dûˋjû traitûˋes par les bibliothû´ques de templating, mais auxquelles cette spûˋcification n'apporte aucune rûˋponse.
Le rafraichissement partiel de templates pose ûˋgalement problû´me. Prenons l'exemple d'un template qui affiche une liste d'articles. û la suite de l'ajout d'un article, nous souhaitons actualiser la vue en insûˋrant uniquement l'ûˋlûˋment du nouvel article, sans toucher aux autres. Or la rûˋfûˋrence logique û la boucle se trouve en principe dans le template, et non dans le DOM dûˋjû gûˋnûˋrûˋ. Il faut donc soit employer une mûˋthode alternative de rendu pour les rafraichissements partiels, soit travailler sur un mûˋcanisme de comparaison pour actualiser uniquement les parties du DOM ayant changûˋ. Ce mûˋcanisme, aussi appelûˋ dirty-checking, est utilisûˋ par plusieurs solutions complexes (notamment AngularJS, mais s'avû´re trû´s consommateur de ressources.
De maniû´re plus gûˋnûˋrale, il semble que le concept de templates statiques dûˋclarûˋs individuellement soit dûˋjû dûˋpassûˋ comparûˋ aux approches modernes dites de data-binding. On ne travaille plus avec des templates isolûˋs, mais avec un ensemble de liens donnûˋes/vue permettant un rafraûÛchissement intelligent et autonome. C'est pourquoi je doute qu'AngularJS ûˋvolue pour reposer sur cet ûˋlûˋment <template> qui s'intû´gre assez mal avec le fonctionnement existant. Je n'irais pas jusqu'û dire que cette spûˋcification est mort-nûˋe, mais son usage est certainement bien plus minoritaire qu'elle ne l'a laissûˋ supposer.
V. Des mauvaises utilisations des Web Components▲
Suite û tous les dûˋfauts ûˋvoquûˋs, parcourons divers exemples existants qui les mettent en ûˋvidenceô :
V-A. Le Web Component minimaliste▲
Un Web Component dont le code est bien trop simple pour justifier sa dûˋclaration comme composant, ou qui ne s'utilise qu'une seule fois.
Exemplesô :
V-B. Le Web-Component tout-en-un▲
Quand on s'amuse û mettre tout le contenu de son site web dans un seul ûˋlûˋment parce que c'est cool, ou que l'on cherche û mettre des Web Components û l'intûˋrieur d'un Web ComponentãÎ
Exempleô : https://github.com/faunt/domrgn
V-C. Le Web Component boûÛte noire ou iframe 2.0▲
Un Web Component que l'on pourrait aisûˋment remplacer par un iframe tout en rûˋduisant le risque de failles de sûˋcuritûˋ. Souvent, il s'agit d'un composant qui charge de multiples scripts externes, avec un code difficile û analyser, trû´s peu de contrûÇle sur le code importûˋ et pouvant contenir d'ûˋventuelles failles XSS. Il peut aussi s'agir d'un service Web notoire qui vient s'installer de maniû´re un peu trop intrusive sur votre site web en chargeant de grosses API propres au fonctionnement du service (ce que les entreprises appellent parfois ô¨ô SDK JavaScriptô ô£, quoi que cela veuille dire).
Exempleô : http://component.kitchen/components/google-map

V-D. Le Web Component anti-standard▲
Un Web-Component qui reprend le fonctionnel d'un standard existant sans utiliser ce standard, ou qui pourrait ûˆtre remplacûˋ par un polyfill.
Exemplesô :
http://garstasio.github.io/file-input/components/file-input/
V-E. Le Web Component qui n'a rien û faire dans HTML▲
Un Web Component qui ne reprûˋsente pas d'ûˋlûˋment, qui n'est pas identifiable visuellement ou qui ne prûˋsente aucun sens sûˋmantique dans le document et peut ûˆtre remplacûˋ par un script explicite.
Exempleô : http://www.polymer-project.org/docs/elements/core-elements.html#core-ajax
V-F. Le Web Component gadget▲
Un Web Component qui n'a aucune raison d'exister, mais qui existeô ; pour le fun, pour la publicitûˋ ou simplement parce qu'on peut le faire. Le point prûˋoccupant est que ces gadgets se retrouvent au mûˆme plan que d'autres composants ô¨ô sûˋrieuxô ô£ dans les sites les rûˋfûˋrenûÏant. Cela amû´ne la question de comment s'assurer de la qualitûˋ et de la pûˋrennitûˋ des composants trouvûˋs sur le net.
Exemplesô :
VI. Conclusion▲
J'ai utilisûˋ l'humour et un ton assez provocateur dans cet article pour mettre en exergue les dûˋfauts des Web Components. Mûˆme si certains aspects de la spûˋcification sont û revoir complû´tement selon moi, tout n'est pas û jeter. Je pense que tous les articles et vidûˋos dûˋjû parus sur le sujet ont bien expliquûˋ en large et en travers les avantages des Web Components, c'est pourquoi je me suis concentrûˋ sur le nûˋgatif ici.
Les Web Components, lorsqu'ils sont correctement utilisûˋs, apportent une meilleure lisibilitûˋ dans les pages HTML comportant beaucoup d'ûˋlûˋments d'interface sophistiquûˋs (ce qu'on pourrait typiquement appeler les web-apps). Ils permettent de modulariser le HTML, de faciliter la maintenance du code et de rûˋduire le risque d'effets de bord et de rûˋgressions fonctionnelles grûÂce û l'isolation apportûˋe par les fragments de document.
Toutefois, il n'y a pas d'alternative avec les ûˋlûˋments standardisûˋs du HTML. Bien qu'il s'utilise au mûˆme niveau qu'un ûˋlûˋment HTML, un Web Component est un enrobage autour d'un ou plusieurs ûˋlûˋments accompagnûˋs de CSS et de JavaScript. Il vaut toujours mieux privilûˋgier l'ûˋlûˋment standard adûˋquat plutûÇt que de vouloir redûˋfinir les propriûˋtûˋs et le comportement d'ûˋlûˋments neutres tels que <div> ou <span> pour arriver û l'objectif dûˋsirûˋ (rappelez-vous l'exemple du datepicker). En effet, les propriûˋtûˋs du composant se limitent au pûˋrimû´tre envisagûˋ par son dûˋveloppeur, contrairement aux ûˋlûˋments standards qui sont adaptûˋs nativement selon le navigateur et le terminal. Ces adaptations ont dûˋjû montrûˋ leur utilitûˋ par le passûˋ, notamment pour les navigateurs mobiles des premiers smartphones. Il est trû´s difficile (impossibleô ?) pour un dûˋveloppeur de couvrir tous les contextes d'utilisation existants aujourd'hui, sans mûˆme envisager ceux de demain. Et si on y consacrait plus d'efforts, la taille du code des composants en accuserait le coup.
Ainsi, pour savoir s'il est lûˋgitime de dûˋfinir un Web Component pour un besoin donnûˋ, voilû ce qu'un ô¨ô bonô ô£ Web Component doit prûˋsenter comme caractûˋristiques selon moiô :
- Il n'existe aucun ûˋlûˋment standard ou en cours de standardisation qui puisse rûˋpondre û ce besoin.
- Il remplit bien la fonction d'ûˋlûˋmentô : il peut ûˆtre identifiûˋ visuellement et placûˋ dans la hiûˋrarchie du document le contenant.
- Il est paramûˋtrable dans une certaine mesureô : s'il devient trop complexe, il est sans doute dûˋcomposable en plusieurs composants.
- Il est rûˋutilisable, y compris û plusieurs endroits d'un mûˆme document.
- Il ne dûˋpend pas du HTML parent dans lequel il se trouve.
- Il est autonome (pas de chargement de scripts externes).
- Il est adaptûˋ û un maximum de terminaux (tailles d'ûˋcran, interfaces souris/tactile, etc.).
- Il est adaptûˋ û un maximum d'utilisateurs (efforts sur l'accessibilitûˋ et le contexte d'utilisation).
- Il ne laisse pas de traces mûˋmoire JavaScript une fois l'ûˋlûˋment supprimûˋ.
- Son code est lisible et ne laisse planer aucun doute sur son fonctionnement interne.
La publication et le rûˋfûˋrencement d'un catalogue de web components est une idûˋe trû´s sûˋduisante aux yeux de nombreux dûˋveloppeurs, et plusieurs sites sont dûˋjû û l'éuvreô : http://component.kitchen/, http://customelements.io/). Nûˋanmoins, il convient de prendre garde û la qualitûˋ et û la pertinence de ces composantsô : faites le tour des diffûˋrents composants dûˋjû proposûˋs dans ces catalogues et vous vous apercevrez que bien peu d'entre eux respectent toutes les caractûˋristiques prûˋcûˋdemment listûˋes.
En rûˋsumûˋ, les Web Components sont un progrû´s car ils normalisent la dûˋfinition et l'intûˋgration de composants d'interface, sans toutefois rûˋvolutionner leur nature elle-mûˆme. Cependant, chaque progrû´s doit ûˆtre utilisûˋ intelligemment et modûˋrûˋment. Les composants sont des boûÛtes noires qui peuvent dissimuler un code de mauvaise qualitûˋ, des risques de sûˋcuritûˋ, des dûˋfauts d'accessibilitûˋ ou des actions trop intrusives sur le reste de la page. Les sites de rûˋfûˋrencement des Web Components devront ainsi privilûˋgier la qualitûˋ sur la quantitûˋ si l'on souhaite que le Web soit bûÂti avec des briques solides.