




I. Principe de base et vocabulaire▲
Par application web, on dûˋsigne un site web proposant davantage que de la simple consultation de contenuô : une interaction riche avec l'utilisateur, une notion de service, une expûˋrience proche de celle d'une application native. Le dûˋveloppement de ce genre d'applications a ûˋvoluûˋ avec toujours plus de logique cûÇtûˋ client, ce qui a amenûˋ û rûˋflûˋchir û l'architecture du code JavaScript et û transposer cûÇtûˋ client des patterns dûˋjû ûˋprouvûˋs cûÇtûˋ serveur, tels que l'architecture multitier ou le patron de conception MVC.
Dans les applications web modernes, les parties client et serveur sont totalement dûˋcouplûˋes et les ûˋchanges sont rûˋduits au minimum en ûˋtant constituûˋs presque exclusivement de donnûˋes sûˋrialisûˋes. Le format le plus populaire actuellement est une API REST exposant les donnûˋes au format JSON. Une fois rûˋcupûˋrûˋes en JavaScript, on retrouve une reprûˋsentation partielle de ces donnûˋes mûˋtier cûÇtûˋ clientô : c'est la couche Modû´le (M).
Ces donnûˋes sont ensuite manipulûˋes et formatûˋes pour venir s'inscrire dans le HTML de la page et former l'interface utilisateur, ce que l'on appelle communûˋment la couche Vue (V).
Ce qui vient relier le Modû´le et la Vue, c'est ce qui nous intûˋresse ici. Dans les architectures MVC (C pour ContrûÇleur), les actions de la couche Vue sur la couche Modû´le sont entiû´rement rûˋgies et formalisûˋes par des contrûÇleurs. Les contrûÇleurs sont des objets qui dûˋcrivent prûˋcisûˋment la maniû´re dont le modû´le est mis û jour suite û un ûˋvûˋnement dans la vue. Ils peuvent aussi notifier les vues qu'un changement a eu lieu dans un modû´le afin de dûˋclencher leur mise û jour. Ainsi, la couche Modû´le ne comporte aucun lien direct vers des ûˋlûˋments de la couche Vue. Tout est bien sûˋparûˋ.
Cette architecture trû´s populaire a donnûˋ naissance û plusieurs dûˋclinaisons avec le temps, dont la MVVM (Model - View - ViewModel) popularisûˋe par Microsoft et sa technologie Windows Presentation Foundation (WPF). On retrouve le principe de base du MVC, mais l'appellation ô¨ô ContrûÇleurô ô£ disparaûÛt pour mettre en avant le rapprochement des couches Vue et Modû´le, qui gagnent en proximitûˋ tout en restant dûˋcouplûˋes. Ces ViewModel, ou modû´les de vue, correspondent aux donnûˋes consommûˋes par les vues et dûˋdiûˋes û la logique de prûˋsentation. Ils sont fortement liûˋs aux modû´les mûˋtier, si bien qu'ils en sont souvent une transposition directe, û la structure presque identique. Il n'y a donc plus de couche ContrûÇleur explicite aux yeux du dûˋveloppeur, mais un mûˋcanisme de synchronisation Modû´le - ViewModel se voulant le plus transparent et autonome possible. Cela se traduit par un gain de productivitûˋ, surtout pour les travaux de prototypage rapide. Mais cela vient ûˋgalement complexifier la couche Vue en introduisant plus de logique et plus de directives spûˋcifiques dans les templates HTML, voire des extensions aux langages comme c'est le cas de React avec JSX.
Dans une architecture MVVM, les vues sont en thûˋorie automatiquement mises û jour lorsque les modû´les dont elles dûˋpendent sont modifiûˋs. Cela implique plusieurs mûˋcanismes û ûˋtudier sûˋparûˋmentô : la dûˋtection de changements (change detection), la rûˋsolution des liaisons associûˋes (change resolution), et la mise û jour du DOM (DOM updating). Ce sont ces trois composantes essentielles qui forment ensemble ce qui est communûˋment appelûˋ data binding. Nous verrons que ces mûˋcanismes sont implûˋmentûˋs de maniû´re diffûˋrente selon les frameworks.
û la sortie d'AngularJS en 2009, Google a fortement marketûˋ sur le terme ô¨ô 2-way data bindingô ô£ ou ô¨ô liaison de donnûˋes û double-sensô ô£. La dûˋmonstration la plus courante de ce mûˋcanisme est une zone de saisie de texte suivie d'un paragraphe avec ce mûˆme texte saisi. Lorsque l'utilisateur vient modifier la zone de texte, le paragraphe est automatiquement mis û jour û chaque frappe. On illustre bien les deux sens de communication vue-modû´le, d'une part en rûˋcupûˋrant la modification sur la zone de texte suite û l'ûˋvûˋnement input, et d'autre part en mettant û jour dans la vue le paragraphe dont le contenu est associûˋ au modû´le correspondant.
Toutefois, ce terme est un abus de langage, car le mode de communication d'un sens û l'autre n'est pas du tout le mûˆme. Dans le sens modû´le vers vue, les ûˋlûˋments de la vue sont manipulûˋs via les API du DOM ou via une modification directe du HTML, selon le framework et le type de changement dans le modû´le. Tandis que dans le sens vue vers modû´le, ce sont des ûˋvûˋnements spûˋcifiques, gûˋnûˋrûˋs par le navigateur suite aux actions de l'utilisateur, qui sont capturûˋs par des ûˋcouteurs prûˋalablement initialisûˋs pour les besoins du data binding. On ne passe donc pas par le mûˆme canal, mais comme la logique derriû´re ces ûˋchanges est de plus en plus automatisûˋe et dissimulûˋe, le dûˋveloppeur finit par ne plus faire la diffûˋrence.
Le 2-way data binding pose plusieurs problûˋmatiques, dont la principale est celle de provoquer des boucles infinies dans certains cas. Un match de ping-pong peut survenir lorsqu'une mise û jour du modû´le entraûÛne une mise û jour de la vue qui elle-mûˆme entraûÛne une mise û jour du modû´le, qui elle-mûˆme entraûÛne une mise û jour de la vue, etc.
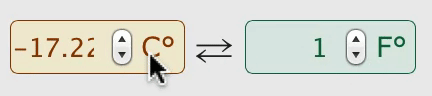
Un exemple simple pour illustrer ce cas est celui d'un convertisseur d'unitûˋs Celsius/Fahrenheit, avec deux zones de saisie dont la valeur de l'une dûˋpend de celle de l'autre. On souhaite que tout changement de valeur d'un des champs relance le calcul et mette û jour la valeur de l'autre champ. Si l'on modifie la valeur du champ Celsius, un ûˋvû´nement ô¨ô changeô ô£ est dûˋclenchûˋ ce qui met û jour les liaisons dûˋpendant de cette valeur. La valeur du champ Fahrenheit est liûˋe û cette valeur par le facteur de conversion, elle est donc mise û jour. Mais cette mise û jour entraûÛne logiquement un autre ûˋvûˋnement ô¨ô changeô ô£ sur la zone Fahrenheit cette fois, et on rûˋpû´te le mûˆme processus dans l'autre sens. Nikita Vasilyev dûˋtaille ce problû´me et compare les implûˋmentations et les rûˋsultats obtenus dans cet article (en anglais).
Ce match de ping-pong peut se rûˋsoudre de diverses faûÏons, les frameworks s'en sortant gûˋnûˋralement bien pour ûˋviter la boucle infinie et rûˋsoudre le problû´me en un certain nombre de passes. Dans tous les cas, cela peut impacter significativement la rûˋactivitûˋ de l'application. C'est une des raisons pour laquelle le 2-way data binding a rapidement acquis une rûˋputation de ô¨ô performance killerô ô£. Cependant, comme on le verra dans la prochaine section, c'est aussi surtout û cause de son implûˋmentation dans Angular 1.x.
On a ensuite fait ûˋvoluer û nouveau le vocabulaire en faisant la promotion du ô¨ô 1-way data bindingô ô£, qui rûˋduit le data binding û un seul sens, gûˋnûˋralement les mises û jour du modû´le vers la vue. Cette application û sens unique empûˆche tout risque de boucle infinie, puisqu'elle offre la garantie que l'ûˋtat de la vue est dûˋterminûˋ par celui du modû´le en un seul cycle. On compte alors sur le dûˋveloppeur pour gûˋrer lui-mûˆme les interactions utilisateur et les ûˋvûˋnements survenant dans la page. Pour faire les choses proprement, celui-ci aura tendance û externaliser ses mûˋthodes d'interaction, et aprû´s quelques semaines, il se rendra compte qu'il vient de rûˋinventer la couche ContrûÇleur. Deux pas en avant, un pas en arriû´re.
Il se peut que vous entendiez ûˋgalement parler de ô¨ô 3-way data bindingô ô£. Cela dûˋsigne une extension de cette liaison vue-modû´le pour inclure ûˋgalement le modû´le persistûˋ cûÇtûˋ serveur, et donc les mûˋcanismes de synchronisation de modû´le qui en dûˋcoulent entre client et serveur. L'abus de langage est encore plus grossier ici puisqu'on identifiera non pas trois, mais quatre liaisons diffûˋrentes. Aussi, la synchronisation de modû´le client-serveur est un procûˋdûˋ asynchrone et restrictifô : cela signifie qu'il s'accompagne de rû´gles de rûˋsolution de conflits, toute l'autoritûˋ ûˋtant confiûˋe au serveur. On trouve ûˋgalement trû´s souvent dans ces solutions divers procûˋdûˋs d'optimisation rûˋseau comme le debouncing, le data-diffing ou la compression. C'est pourquoi l'idûˋe d'une liaison instantanûˋe et infaillible entre la vue et la base de donnûˋes, telle qu'elle est vendue par les services tiers utilisant ce terme, est donc trû´s ûˋloignûˋe de la rûˋalitûˋ.
II. AngularJS 1.x▲
En brefô :
- dûˋtection de changementsô : digest loop et dirty checkingô ;
- rûˋsolution des liaisonsô : watchers et dependency tracking û la liaison du templateô ;
- mise û jour du DOMô : aprû´s digestion, via des directives spûˋcialisûˋes.
La version 1.x du framework de Google met en avant le 2-way data binding, et introduit divers concepts spûˋcifiques û Angular. Tout d'abord, les donnûˋes concernûˋes par le data binding sont placûˋes dans des objets conteneurs particuliers nommûˋs scopes. Les expressions des templates Angular sont exûˋcutûˋes dans le contexte de ces scopes. Les parties dynamiques des templates, comme les boucles ou les conditions, peuvent crûˋer des scopes enfants qui hûˋritent des propriûˋtûˋs de leurs parents, un peu û la maniû´re des scopes en JavaScript.
La dûˋtection de changements sur Angular 1.x repose sur le fait que toutes les modifications du modû´le soient rûˋalisûˋes dans un contexte d'exûˋcution contrûÇlûˋ par Angular. C'est pour ûÏa que beaucoup de choses doivent ûˆtre rûˋalisûˋes ô¨ô û la faûÏon Angularô ô£ pour que le data binding fonctionne bien. On remplace ainsi onclick par ng-click et setTimeout par $timeoutô : ces attributs et services spûˋcifiques û Angular sont des emballages (on parle de wrappers) autour de fonctionnalitûˋs de base en JavaScript.
Le principal intûˋrûˆt de ces wrappers est d'indiquer û Angular qu'û la fin de l'exûˋcution du code, le scope associûˋ doit rentrer dans une phase de digestion (le digest cycle). Cette phase de digestion consiste û vûˋrifier s'il y a eu des modifications dans le modû´le, et quelles sont les expressions associûˋes û mettre û jour. Puisque cette phase intervient une fois toutes les modifications du modû´le effectuûˋes, Angular n'a pas d'autre choix que de vûˋrifier une û une les expressions pour voir si quelque chose a changûˋô : c'est ce qu'on nomme le dirty checking.
Ce nom n'est pas trû´s flatteur et pour cause, il travaille beaucoup pour souvent ne rien trouver. Angular lance rûˋguliû´rement ce mûˋcanisme, notamment lorsqu'il perûÏoit des ûˋvû´nements du navigateur. Un ûˋvû´nement peut ûˆtre une interaction utilisateur, une rûˋponse û une requûˆte AJAX, un timer, etc. Malgrûˋ ces prûˋcautions, il arrive souvent que le dûˋveloppeur ait û indiquer manuellement û Angular de lancer une phase de digestion aprû´s une opûˋration asynchrone, avec $scope.$applyô :
socket.on("message", function(data){
ô ô $scope.$apply(function () {
ô ô ô ô $scope.messages.push(data.message);
ô ô ô })
})Le dirty checking implique ûˋgalement que seul l'ûˋtat final du modû´le est pris en compte, et les modifications intermûˋdiaires qui ont pu avoir lieu ne sont donc pas prises en compte. Donc dans l'exemple suivant, le texte du bouton ne sera jamais mis û jour, mûˆme une fraction de seconde, pour afficher les messages bar/baz/qux.
$scope.message = "foo";
$scope.changerMessage = function(){
ô ô $scope.message = "bar";
ô ô $scope.message = "baz";
ô ô $scope.message = "qux";
ô ô $scope.message = "foo";
}<button ng-click="changerMessage()">{{message}}</button>Cela permet d'optimiser la phase de mise û jour du DOM, mais peut surprendre le dûˋveloppeur. C'est pourquoi on conseille gûˋnûˋralement de regrouper au mûˆme endroit les modifications du modû´le, et d'ûˋviter de requûˆter/manipuler le DOM avant une phase de digestion.
Si le dirty checking a dûˋtectûˋ des changements, il est exûˋcutûˋ une seconde fois au cas oû¿ un watcher viendrait changer û nouveau le modû´le suite û ces changements (comme dans l'exemple ping-pong). Le dirty checking est au minimum exûˋcutûˋ deux fois pour essayer d'assurer une certaine stabilitûˋ des modû´les. L'implûˋmentation de ce mûˋcanisme dans Angular est donc particuliû´rement coû£teuse en performances, d'une part û cause du principe mûˆme du dirty checking, et d'autre part car il est impossible de prûˋdire le nombre de passes requises lors du cycle de digestion.
Concernant la rûˋsolution des liaisons, Angular s'occupe lors de la lecture du template d'inscrire des watchers sur les propriûˋtûˋs du scope. Par exemple, quand vous ûˋcrivez {{message}} dans un template, Angular va inscrire un watcher sur la propriûˋtûˋ message pour mettre û jour ce néud texte lorsque cette propriûˋtûˋ change. On peut ûˋgalement ajouter manuellement ces watchers avec $watch. Le fonctionnement de ces watchers est trû´s proche d'un publisher/suscriber. Enfin, la mise û jour du DOM se fait classiquement selon le type de directive utilisûˋ dans le template (néud texte, modification des attributs, modification de la liste de classes, etc.).
Avec Angular 2, Angular s'amûˋliore nettement en matiû´re de dûˋtection de changements, notamment en catûˋgorisant les propriûˋtûˋs du modû´le et leurs liaisons. En ayant connaissance des propriûˋtûˋs immutables et observables, le cycle de digestion devient plus ô¨ô intelligentô ô£ et se trouve largement optimisûˋ. Vous trouverez plus d'explications dans cet article (en anglais) de Viktor Savkin.
III. React▲

En brefô :
- dûˋtection de changementsô : API de changement d'ûˋtatô ;
- rûˋsolution des liaisonsô : rendu complet d'un DOM virtuelô ;
- mise û jour du DOMô : virtual DOM diffing.
La stratûˋgie de data binding de React est trû´s diffûˋrente, voire opposûˋe û celle d'Angular. Angular concentre ses efforts sur la dûˋtection de changements et la rûˋsolution prûˋcise des liaisons impactûˋes dans le but de simplifier l'ûˋtape de mise û jour du DOM. Tandis que React opte pour rûˋinterprûˋter tous les templates et toute l'UI û chaque fois qu'un ûˋvû´nement survient. Mais il dispose d'un atout de taille pour optimiser ce processusô : le DOM virtuel (virtual DOM), une reprûˋsentation abstraite et lûˋgû´re du DOM en purs objets JavaScript bien plus rapides û manipuler que les ûˋlûˋments du DOM eux-mûˆmes. Une seconde phase, le diffing, consiste û comparer la nouvelle version du DOM virtuel avec le vûˋritable DOM, afin d'en calculer un diffûˋrentiel. C'est ce diffûˋrentiel qui sera finalement appliquûˋ pour mettre û jour le DOM, avec le minimum d'opûˋrations requises et donc le maximum de performances.
Ainsi le dûˋveloppeur n'a plus besoin de se prûˋoccuper de l'ûˋtat de son DOM puisque toute l'UI est redessinûˋe û chaque fois. On retrouve en quelque sorte la facilitûˋ dont on disposait û l'ûˋpoque du rendu du HTML cûÇtûˋ serveurô : la page et le contexte JavaScript ûˋtaient alors systûˋmatiquement rûˋinitialisûˋs û chaque action.
React ne s'occupe pas trop de la couche Modû´le, mais l'ûˋquipe de Facebook conseille de l'associer avec Flux, qui est plus un choix d'architecture qu'un framework. Sans entrer dans les dûˋtails, car ce n'est pas l'objet de cet article, le principe est d'ûˋtablir un flux unidirectionnel pour la propagation des actions depuis la vue jusqu'aux modifications sur les modû´les (appelûˋs stores pour Flux). Il n'y a donc aucun risque de boucle infinie puisque toutes les actions passent par un unique dispatcher, permettant un contrûÇle total sur l'ûˋtat applicatif. Ce choix d'architecture s'associe donc trû´s bien avec React puisque le rendu diffûˋrentiel du DOM est la derniû´re ûˋtape requise pour mettre û jour l'interface utilisateur une fois ce nouvel ûˋtat applicatif ûˋtabli.
Le DOM virtuel est ainsi un moyen trû´s simpliste, voire naû₤f, de mettre û jour efficacement le DOM û partir du moment oû¿ l'on sait que le modû´le a ûˋtûˋ modifiûˋ, peu importe comment. Il faut toutefois indiquer û React que le modû´le a changûˋ, et il n'y a pas d'intelligence particuliû´re pour cette dûˋtection de changements. C'est au dûˋveloppeur de l'indiquer explicitement en appelant des mûˋthodes telles que setState, ou en utilisant une architecture de type Flux qui conditionne lû aussi la maniû´re dont les modû´les sont modifiûˋs.
IV. Vue▲

En brefô :
- dûˋtection de changementsô : getter/setters ES5ô ;
- rûˋsolution des liaisonsô : watchers et dependency tracking û la liaison du templateô ;
- mise û jour du DOMô : au prochain tick, via des directives spûˋcialisûˋes.
Vue.js s'est fait connaûÛtre pour sa simplicitûˋ et son approche composants qui le rapproche de React en matiû´re d'expûˋrience de dûˋveloppement. Mais sur le plan du data binding, ses mûˋcaniques ressemblent davantage û AngularJS. Il dispose tout comme Angular d'une syntaxe spûˋcifique dans les templates pour diffûˋrencier les types de liaison (interpolation de texte, attributs, conditions, bouclesãÎ), et des watchers sont initialisûˋs lors de la lecture du template. Les expressions du template sont alors exûˋcutûˋes une premiû´re fois dans un mode ô¨ô tracking de dûˋpendancesô ô£, qui recense toutes les propriûˋtûˋs qui ont ûˋtûˋ touchûˋes (grûÂce aux getters ES5) et permet de construire un arbre de dûˋpendances.
La mise û jour du DOM se fait classiquement d'une maniû´re similaire û Angularô : les watchers dûˋclenchent la mise û jour des liaisons dûˋpendant du modû´le modifiûˋ, et ces liaisons sont conûÏues pour modifier le DOM de la maniû´re la plus efficace possible selon leur fonction. Une petite nuance pour Vue est que le framework attend la fin de la boucle d'exûˋcution courante pour lancer cette mise û jour du DOMô ; l'ûˋquivalent d'un setTimeout(render, 0) en somme.
C'est sur la dûˋtection de changements que Vue se distingue des autres frameworks. Alors qu'Angular utilise des wrappers et du dirty checking, et que React ou Backbone ont recours û des API spûˋcifiques pour modifier les modû´les, Vue utilise quant û lui les getters/setters. Cette fonctionnalitûˋ assez peu connue des dûˋveloppeurs JavaScript est arrivûˋe avec la norme EcmaScript 5, qui est aujourd'hui trû´s bien supportûˋe sur la majoritûˋ des navigateurs (si on oublie IE<9).
Pour rappel, les getters/setters permettent d'intercepter et d'exûˋcuter du code quand une propriûˋtûˋ d'un objet est accûˋdûˋe en lecture ou en ûˋcritureô :
var object = (function(){
ô ô var hiddenProperty;
ô ô return {
ô ô ô ô get property(){
ô ô ô ô ô ô console.log("accû´s en lecture û la propriûˋtûˋ")
ô ô ô ô ô ô return hiddenProperty
ô ô ô ô },
ô ô ô ô set property(value){
ô ô ô ô ô ô console.log("accû´s en ûˋcriture û la propriûˋtûˋ")
ô ô ô ô ô ô hiddenProperty = value
ô ô ô ô }
ô ô }
})();> object.property = 42;
accû´s en ûˋcriture û la propriûˋtûˋ
42
> ++object.property
accû´s en lecture û la propriûˋtûˋ
accû´s en ûˋcriture û la propriûˋtûˋ
43Lorsque vous instanciez un objet Vue, vous devez passer en argument un objet contenant toutes les donnûˋes qui seront utilisûˋes par cette vue. Vue va ensuite produire une version ô¨ô proxyô ô£ de cet objet, qui prûˋsente exactement la mûˆme structure mais dont les propriûˋtûˋs ont ûˋtûˋ redûˋfinies avec Object.defineProperty et des getters et setters qui permettent û Vue de savoir quand une propriûˋtûˋ est lue ou modifiûˋe. C'est cet objet proxy qui constituera donc le modû´le de vue (qui n'a jamais aussi bien portûˋ son nom).
L'avantage est que ce modû´le ô¨ô proxyfiûˋô ô£ s'utilise exactement de la mûˆme faûÏon que le modû´le original que vous avez passûˋ au constructeur. Vous n'avez rien û faire de particulier pour que la dûˋtection de changements fonctionneô : tout se met û jour tout seul. La documentation parle de modû´le ô¨ô rûˋactifô ô£. Pour le dûˋveloppeur, c'est donc beaucoup plus simple comparûˋ au principe de wrapper et de contexte d'exûˋcution d'AngularJS. Vue est le seul ici û savoir immûˋdiatement et prûˋcisûˋment ce qui a changûˋ dans vos modû´les, contrairement û Angular qui doit vûˋrifier tous les modû´les et React qui doit rûˋinterprûˋter tous les templates.
Cependant, comme rien n'est parfait, ce mûˋcanisme prûˋsente quelques limitations propres aux getters/setters ES5. Il faut en effet que toutes les propriûˋtûˋs û surveiller soient initialement prûˋsentes dans le modû´le lors de l'initialisation de la vueô ; par dûˋfaut, ces modû´les ne peuvent donc pas comporter de propriûˋtûˋs dynamiques qui viennent s'ajouter ou se retirer pendant l'exûˋcution. Certaines opûˋrations peuvent aussi ne pas ûˆtre dûˋtectûˋes, comme lorsque l'on vient agrandir la taille d'un Array en manipulant directement les index. Le framework compense ces lacunes en proposant une mûˋthode $set pour venir effectuer ces modifications tout en notifiant le ViewModel.
Les mûˋcaniques de Vue sont donc moins ambitieuses et rûˋvolutionnaires qu'un contexte d'exûˋcution d'Angular ou un virtual DOM de React, mais fonctionnent tout aussi bien. Le framework se contente d'utiliser les parties de JavaScript qui semblent les plus adûˋquates pour les diffûˋrents besoinsô : setters pour la dûˋtection de changements et getters pour le tracking de dûˋpendances.
V. Conclusion▲
La tendance gûˋnûˋrale est û la simplification et û l'automatisation des ûˋchanges entre vue et modû´le. C'est prûˋcisûˋment l'objectif du data binding, un mûˋcanisme implûˋmentûˋ de diverses maniû´res selon les frameworks. Pour y parvenir, on peut mettre en place des solutions trû´s audacieuses. Le DOM virtuel, par exemple, est une idûˋe que l'on aurait pu techniquement mettre en place il y a des annûˋes, mais qui ne s'est dûˋmocratisûˋe que tout rûˋcemment. Il faut dire que ce genre d'idûˋes amû´ne son lot de bouleversements et brise beaucoup de conventions, comme les choix de sûˋparation des couches et des langages.
Le langage JavaScript ûˋvolue ûˋgalement pour tenter d'offrir nativement des mûˋcaniques utiles au data binding. Mais le paysage ûˋvolue rapidement. Alors qu'en 2014, on nous promettait monts et merveilles avec Object.observe(), ce brouillon de spûˋcification a finalement ûˋtûˋ abandonnûˋ par son auteur quand il s'est rendu compte qu'il ne collait plus au fonctionnement des nouveaux frameworks MVVM. Il reste cependant l'API Proxy apparue avec la norme ES6 et qui est supportûˋe depuis peu par le trio Chrome/Firefox/Edge sur desktop. Proxy est un bon candidat pour rûˋvolutionner une fois de plus les mûˋcaniques de data binding. Les proxies permettent en effet de pallier les lacunes des getters/setters ES5 tout en simplifiant le code cûÇtûˋ framework. Une fois qu'ils seront plus largement supportûˋs, on verra sans doute des solutions de data binding minimalistes avec les mûˆmes capacitûˋs que nos mastodontes actuels.
Autour des mûˋcaniques de data binding pur, d'autres sujets sont venus s'ajouter aux dûˋbats. L'approche composants et les Web Components ont changûˋ la faûÏon dont on modularisait traditionnellement notre code front-end. Alors qu'il ûˋtait prûˋconisûˋ il y a quelque temps de sûˋparer nos fichiers selon leur fonction (templates, services, modû´les, contrûÇleurs), on observe aujourd'hui une tendance û privilûˋgier une sûˋparation par fonctionnalitûˋ et par blocs identifiables de l'interface utilisateur. Chaque vue a maintenant son modû´le de vue, et on regroupe sans complexe templates et logique de prûˋsentation dans des ûˋlûˋments qu'on pensait enterrûˋs et oubliûˋsô : c'est le retour des <script> et <style> inlineô ! Les template strings d'ES6 permettent ûˋgalement de stocker les templates HTML sous forme de strings JavaScript, mettant fin û l'ûˋpoque des <script type="text/template">. Cette dûˋcomposition reflû´te davantage le fonctionnel de l'application et moins les engrenages qui se cachent derriû´re.
D'autres thûˋmatiques comme la programmation rûˋactive fonctionnelle ou l'immutabilitûˋ des modû´les ont surfûˋ sur la vague React pour revenir sur le devant de la scû´ne JS. Tout ceci n'est pas encore bien dûˋmocratisûˋ, mais leur introduction dans des frameworks populaires (comme Angular 2 avec RxJS) devrait peut-ûˆtre changer la donne. Avec ces nouveaux paradigmes, on cherche û centraliser l'ûˋtat applicatif (voir cet excellent talk de Andre Medeiros pour en savoir plus). Ce serait alors un gros coup de pouce aux solutions de DOM virtuel et incrûˋmental , qui excellent dans les mises û jour totales et agnostiques du DOM.
En conclusion, derriû´re le terme relativement simple de ô¨ô data bindingô ô£ se cache une multitude de concepts et de mûˋcaniques qui n'ont pas cessûˋ d'ûˋvoluer depuis le dûˋbut de ce siû´cle. Ces ûˋvolutions sont parfois radicalement diffûˋrentes entre elles et arrivent pourtant û coexister sur la scû´ne JavaScript. On mûˋlange une fois de plus les paradigmes, ce qui fait de ce langage un cas trû´s particulier dans le monde de la programmation, avec une communautûˋ trû´s diversifiûˋe dans ses compûˋtences et appûˋtences.
VI. Remerciements▲
Je tiens û remercier mon ami Quentin Focheux pour la relecture technique de cet article, ainsi que Damien Genthial et f-leb pour leur relecture orthographique de qualitûˋ.